Кем быть? Часть 3
Новости
Стать коллегой преподавателя спустя год после окончания университета? Все возможно в рассказе Анастасии Кравцовой, выпуск ОТиПЛ 2018.
На самом деле первый шаг на пути к работе в сфере обработки естественного языка (natural language processing, NLP) я сделала еще учась на четвертом курсе. Тогда через выпускницу ОТиПЛа (один из плюсов сообщества маленькой кафедры — большие возможности для нетворкинга, т.к. многие друг друга знают) подвернулась подработка в стартапе MrBot. На первом в жизни собеседовании меня среди прочего попросили развернуть список не через метод reverse. И тут на помощь пришла первая палочка-выручалочка — спецкурс по программированию на Python, где на одном из первых занятий рассказывалось про срезы и в частности [::-1].
Получив 30 июня 2018 года диплом бакалавра, в июле я приобрела себе нового друга в лице HeadHunter. Однако новый приятель оказался несговорчивым и молчал практически весь месяц. В августе рынок труда начал оживать, и я оказалась на собеседовании в Исследовательском центре Samsung. Тогда стартовал проект по локализации голосового помощника Bixby для русского языка и набирали в том числе комплингвистов. Во время собеседования я в очередной раз мысленно вознесла оды курсу прикладной математики (в любой непонятной ситуации говори «перцептрон»), а также синтаксиса, потому что довольно неожиданно попросили нарисовать дерево составляющих и написать правила вывода. Здесь я получила свой первый оффер и с начала сентября началось жонглирование работой и учебой в магистратуре. Помимо уже упоминавшегося питона мне также пригодились оба иностранных языка (немецкий и испанский), которые я учила в бакалавриате.
Спустя время проект по ряду причин заморозили, и в конце апреля меня снова выбросило на рынок труда. В этот раз я успела пройти три собеседования. Одно из них было в лабораторию нейронных систем и глубокого обучения МФТИ, в которой занимаются исследованиями в области разговорного искусственного интеллекта и разработкой библиотеки DeepPavlov. Вышло успешно, и с тех пор я осела на Физтехе за соседним столом с Алексеем Сорокиным.
Первое время мои задачи в основном были связаны со сбором, разметкой и валидацией данных для NLP-моделей через краудсорсинговую платформу Яндекс.Толока. Для ее освоения среди прочего пришлось познакомиться с JavaScript. Здесь мне пригодился опыт с C#, который мы учили на первом-втором курсах бакалавриата, поскольку часть синтаксиса этих языков программирования схожа. На самом деле Толока довольно полезный инструмент не только для прикладных, но и теоретических лингвистов — например, для получения или оценки языковых суждений, поскольку на платформе работают носители разных языков и можно подобрать исполнителей под свои нужды.

Постепенно круг задач стал расширяться. Сейчас среди прочего я пробую применять методы NLP для автоматической проверки ЕГЭ и занимаюсь исследованиями в области автоматического исправления грамматических ошибок (последнее, к слову, было темой моего магистерского диплома, который я защищала уже в НИУ ВШЭ).
В заключение — пара советов студентам с интересом к сфере прикладной лингвистики:
- не халтуря осваивать математику и программирование;
- при этом не забывать и про теорлинг, поскольку иметь в нем прочную базу также важно: даже разработчики библиотеки transformers из HuggingFace с зоопарком передовых нейросетей для решения NLP-задач говорят, что в область должна вернуться лингвистика per se;
- подписаться на slack OpenDataScience, где среди прочего есть большой канал про NLP, который интересно почитывать, чтобы оставаться в струе.
И, пользуясь случаем, отдельное пожелание уже к руководству кафедры: приглашать на коллоквиумы отделения не только теоретических лингвистов, но и компьютерных, а также нейролингвистов, чтобы студенты и не только могли прочувствовать разные стороны такой богатой и захватывающей науки о языке.

Как весёлые домашние задания по АОЗРу (подробности в видео) превратились спустя два года в интересную работу? Секреты мастерства от Анны Ахметовой, ОТиПЛ, выпуск 2019.
— Я работаю в АБК или Актив Бизнес Консалт. Наша компания развивает новые технологии. АБК применяет свои разработки для возврата просроченных задолженностей как подрядчик или продает их сторонним компаниям. Мы с коллегами занимаемся речевыми технологиями: синтезом и распознаванием, а еще у нас есть свой робот-оператор. Основной проект, в котором я задействована, связан как раз с синтезом речи.
Чтобы синтезировать речь человека, нужно собрать корпус — аудиозаписи с расшифровкой, то есть с размеченным текстом. Я слежу за тем, как записываются дикторы, составляю корпуса для записи, улучшаю уже записанные корпуса, участвую в разработке новых правил разметки текста. Улучшение корпусов это задача, которой можно заниматься бесконечно, потому что в синтезе всегда есть места, которые можно и нужно улучшить.
Мне интересно работать с человеческой речью. После того, как долго учился и получил теоретическое представление о том, как работают язык и речь, применять эти знания для решения продуктовых задач и видеть результаты своих трудов оказывается супер как интересно! Это очень мотивирует меня работать, потому что я знаю, что можно «потрогать» результаты — послушать синтез, протестировать его, сравнить с тем, как звучало раньше. Ещё странно и прикольно, что тебе звонит робот-оператор из банка, а это голос человека, которого ты почти каждый день слушаешь на работе :)
Мне нравится проводить самостоятельные мини-исследования для отдельных задач. Тут уже я стала понимать, что образование на ОТиПЛе сделало мою «исследовательскую» жизнь в сто раз проще: я знаю, с каких работ стоит начать разбираться в некоторых вопросах, с какой стороны лучше подойти к решению, какие источники стоит использовать. Мои коллеги не чувствуют себя так уверено в рисерче. Я могу объяснить программистам, почему что-то устроено так, а не иначе, на что стоит обращать внимание в первую очередь и почему какие-то явления в языке важны для нашей цели. Лингвистическое образование помогает заметить особенности записи дикторов или разметки, которые иначе были бы либо вообще пропущены другим специалистом, либо всплыли бы значительно позже.
Студентом ты часто задумываешься, что ты умеешь и как сможешь это применить. Я довольна, что училась на ОТиПЛе, и считаю, что это было реально полезное и вообще крутое образование. Но понимать это я начала только когда вышла на работу :)

Еще один рассказ в нашей рубрике #ОТиПЛ_кем_быть не обошелся без упоминания некоторого канала в Slack. Какого именно и как это связано с работой лингвистов? Внимательно ищите ответ в рассказе Никиты Сыхраннова, выпуск ОТиПЛ 2019.
— Еще во время обучения на ОТиПЛе я начал делать первые попытки построить карьеру в NLP (обработке естественного языка). Откликнувшись на вакансию, о которой узнал от коллег, я попал в Исследовательский институт Samsung, где работал на проекте по локализации голосового помощника Bixby 2.0. Имея смутное представление о том, что меня ждет, я почти не готовился к собеседованию, но, к моему удивлению, многие вопросы оказались на знакомые темы: основы Python, контекстно-свободные грамматики, регулярные выражения, специфические типы данных для работы с языком (префиксные деревья) — и, вероятно, что-то еще, но спустя два года вспоминается только это. Еще большим удивлением было узнать, что интервью я прошел.
Проработав в Samsung чуть больше полугода и приобретя огромное количество базовых знаний и навыков в написании кода и машинном обучении (здесь отдельное спасибо нужно сказать программе финансирования курсов на Coursera, которая действовала в компании), я вновь оказался на рынке труда — в связи с завершением моего проекта, — но в этот раз ждать помощи случая не приходилось. Походив в течение месяца на собеседования в разные компании, я оказался в организации, где и работаю по сей день: в Сбербанке.

Сначала я трудился в команде, которая занимается интеллектуальной обработкой документов, извлечением из них информации в структурированном виде. Именно здесь мне довелось пройти «боевое крещение» для настоящей работы в сфере Data Science: за год я успел поработать над множеством разных задач, освоив несколько новых фреймворков и значительно укрепив свои знания в области нейронных сетей и их применения на практике. Естественно, поначалу мне доставались наиболее рутинные задачи, но, решая их и подспудно впитывая опыт и стиль работы старших коллег, я начинал чувствовать себя значительно увереннее и свободнее, а в последние несколько месяцев и вовсе занимался созданием с нуля модели исправления опечаток. Результатом этой работы, скажу без ложной скромности, я немного горжусь.
Недавно я перешел в департамент SberDevices, где разрабатываются умные устройства и виртуальные ассистенты, поэтому можно сказать, что произошло своего рода возвращение к истокам :) Впечатление от этой команды у меня пока сугубо положительное: видно, что уровень технологических компетенций и культуры работы с данными здесь на порядок выше, чем где-либо еще, где мне довелось поработать, а по корпоративной культуре SberDevices куда больше напоминает IT-компанию, чем подразделение банка.
Возможно, прозвучит несколько неожиданно и контринтуитивно, но с наибольшей теплотой и признательностью я вспоминаю фундаментальные лингвистические курсы: введение в специальность и общая морфология В. А. Плунгяна, синтаксис Е. А. Лютиковой, теория дискурса А. А. Кибрика, общая семантика И. М. Кобозевой, формальная семантика С. Г. Татевосова. Дело в том, что именно эти знания дают студенту базовое понимание феномена языка и представление о языковом разнообразии, знакомят с теоретическими концептами, созданными учеными-лингвистами за последнее столетие. Мне кажется, это и следует считать главным конкурентным преимуществом выпускников нашего отделения перед студентами-технарями, изучавшими только математику и прикладные дисциплины. Кажется, что многие прорывы в области связаны с осмыслением фундаментальных представлений об устройстве языка: так можно сказать и об LSTM (прим.: нейронные сети с долгой краткосрочной памятью), и о механизме внимания, который лег в основу архитектуры Transformer. Тем не менее, здесь я вынужден заметить, что самостоятельному изучению технических областей я также посвятил немало времени: это и теория алгоритмов, и «классическая машинка», и нейронные сети, и математический анализ с линейной алгеброй. К счастью, с повсеместным переходом обучения в онлайн (я говорю даже не о событиях последних месяцев, а об общих тенденциях в образовании), все необходимые знания доступны в пару кликов мышкой.
Наконец, нельзя не вспомнить добрым словом курсы Н. В. Лукашевич (информационный поиск и искусственный интеллект) и А. А. Сорокина (так много, что всех и не припомнить). Именно они развивают у студентов необходимый кругозор в области автоматической обработки естественного языка. Иначе как героическими их усилия по развитию компьютерно-лингвистических компетенций у студентов отделения назвать трудно, но очень надеюсь, что в будущем в их строю прибавится бойцов :)
Что я мог бы посоветовать студентам ОТиПЛа, которые задумываются о карьере в области NLP или Data Science? Наверное, не откладывать на завтра получение релевантного опыта: это могут быть самостоятельные или командные мини-проекты, стажировки, курсы. Полезно будет порешать задачи на LeetCode и разобраться в основных алгоритмах поиска и сортировки. Если чувствуете в себе силы, можно попробовать поучаствовать в развитии open-source проектов или побороться за медали в соревнованиях на Kaggle. Совмещать обучение в университете, например, с работой part-time совсем не трудно, а польза от этого в дальнейшем будет значительная. Впрочем, делать это в ущерб учебе я не советую: вполне вероятно, что расширить кругозор в фундаментальных областях потом уже не удастся. А, и еще я рекомендую разнообразить окружающее вас информационное пространство источниками по теме: например, присоединиться к каналу Open Data Science в Slack или телеграм-каналу DL in NLP.
Что делать, если вы родились слишком поздно, чтобы создавать языки программирования, но слишком рано, чтобы развивать искусственный интеллект? Вдохновляться примером Татьяны Шавриной, выпуск ОТиПЛ 2016.
— В тот год, когда я поступала, у нас в ходу была шуточка: “Ты родился слишком поздно, чтобы создавать языки программирования, ты родился слишком рано, чтобы развивать искусственный интеллект”. С этой мыслью я начала потихоньку работать с 1-го курса: переводила в Нацкорпусе PDF советских журналов в html. В тот момент казалось, что работа в сфере айти недостижимо далека, и при этом столь же и скучна. ИИ ведь не получится.

На первом курсе больше всего хотела изучать древние языки: ходила на спецкурс по санскриту, грабару, потом еще были, конечно, старослав и латынь. Потом французский, армянский, финский — про языки не могу думать иначе как про фрукты на шведском столе университета.
Введение в специальность же меня просто поглотило. Огромное влияние научных руководителей — В.А.Плунгяна, В.И.Беликова, А.А.Сорокина — вдохновляло во всем разобраться и все разобрать. В лингвистике практически все темы мне интересны: нейролингвистика, психолингвистика, глоттохронология, формальная семантика — в этом плане, я, наверное, довольно поверхностный специалист, зато очень широкоповерхностный. (На работе меня часто спрашивают об этимологии слова/фамилии — у меня возникает 2-3 версии, обычно неправильные.) Да, работа!
Со второго курса я стала работать в проекте Генерального Интернет-Корпуса русского языка — подбирать ресурсы для скачивания, фильтровать материалы, проводить статистические эксперименты, строить модели классификации текстов и т.д. Совмещение работы и учебы в принципе помогало достаточно сильно — где-то чисто психологически (благодаря ОТиПЛу стало ясно, что я не безнадежна в программировании), а где-то и практически (подтягиваются навыки, закрепляются знания и быстрое принятие решений).
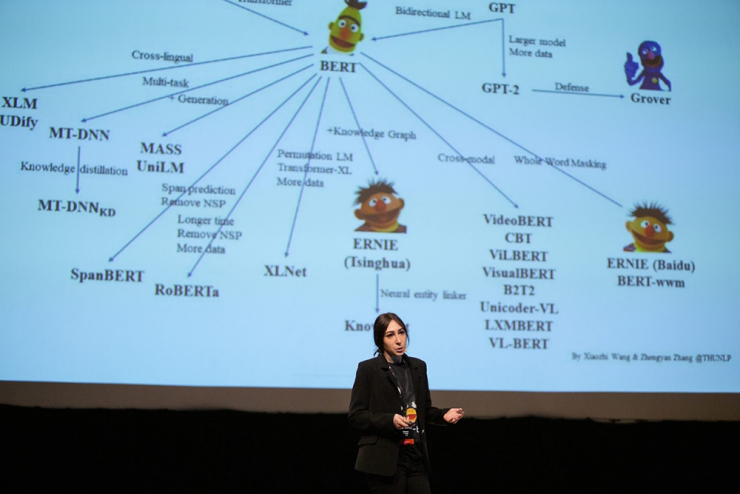
Уже во время магистратуры в Школе Лингвистики ВШЭ я дополнительно прошла годовую программу на ФКН по практическому машинному обучению. Тогда же пришла идея собрать свой собственный корпус, чтобы он был открытый, объемный и полный разнообразной разметки под задачи ML — так получился корпус “Тайга”, открытый корпус для машинного обучения.
После первого года магистратуры я пошла работать на полный день, то есть 60 часов в неделю, как оказалось потом. Прототипировала NLP-инструментарий на питоне в компании 1С, а вечером ехала в магистратуру. Но инженерная наука дается легко, если хоть раз изучал системы правил генеративной грамматики :)
Сейчас я лидер команды исследований и разработки в NLP в Сбербанке, офис Chief Data Science: в команде работают как выпускники школы лингвистики, так и МФТИ, МехМат МГУ, а еще есть писатель. Мы занимаемся большими нейросетевыми моделями — трансформерами, универсальными языковыми моделями. Их интерпретация и построение на их основе более сложных и развитых интеллектуальных систем — сложная задача. Так, например, задача понимания естественного языка (Natural Language Understanding) неотрывна от моделирования механизмов мышления, и создавать инструментарий для оценки языковых моделей приходится с опорой на логику, синтаксис, семантику.
Достаточно долгое время технологии обработки языка (NLP) практически не интересовались фундаментальными проблемами языка (отсюда и известные всем цитаты). Сейчас мы вплотную подошли к рубежу, когда продвижение вперед приносит мультидисциплинарное знание — лингвистика, нейронауки, психология.
Я бы сказала, что cамая большая задача для современного NLP — стать обратно инструментом познания. (Так это уже было с появлением корпусной лингвистики.)
Инженерия — это хорошо, но то, что мы можем узнать из универсальных, многоязычных моделей языка, потенциально более важно.
Поступление на ОТиПЛ было определенно самым дорогим решением в жизни — три года перед этим были подчинены стремлению попасть туда, + 4 года бакалавриата на кафедре, + вся жизнь после ОТиПЛа никогда не будет прежней :)
Мой блог:
https://tatianashavrina.github.io/
Хабр:
https://habr.com/ru/users/rybolos/posts/
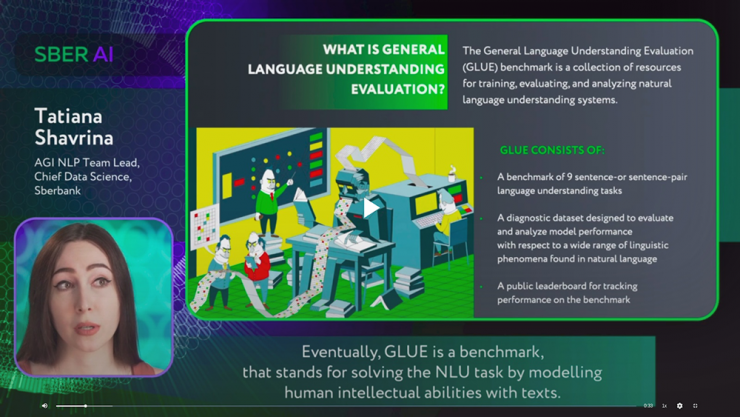
Russian SuperGLUE
http://russiansuperglue.com
Корпуса:
Omnia Russica https://omnia-russica.github.io
Taiga (a lot of trees) https://tatianashavrina.github.io/taiga_site/
От дипломной работы до работы — один шаг. И этот шаг сделала Ольга Черепанова, кандидат филологических наук, выпуск ОТиПЛ 2015
— Незадолго до окончания аспирантуры ОТиПЛа МГУ в 2018 году я начала подумывать о том, чтобы найти постоянную работу вместо фриланса, и обновила резюме на HeadHunter. Я даже ещё не начала самостоятельно искать какие-то варианты, когда мне написал представитель компании МТС ИТ (сегодня — Центр искусственного интеллекта МТС) и предложил рассмотреть вакансию разработчика-лингвиста. В качестве требований к кандидату числились знание основ программирования, теории вероятности, математической статистики, методов и алгоритмов Text Mining, а также опыт работы с системами контроля версий (Git); в числе желательных навыков — умение работать с регулярными выражениями, знание Python и JavaScript. С Python я была знакома благодаря кафедральным спецкурсам, двум проектам на парах по автоматической обработке естественного языка, а также пройденным курсам на Courserа. Также я рассчитывала на какие-то остаточные знания с матстата, матлогики, математической теории грамматик. А вот с JavaScript и гитом пришлось познакомиться непосредственно перед собеседованием. Этого оказалось вполне достаточно для первого времени.

На первом этапе мне прислали тестовое задание — надо сказать, я до сих пор не уверена, насколько правильно я его выполнила. Тем не менее, пару дней спустя меня пригласили на собеседование в офис, где я познакомилась со своим будущим руководителем.
В первую очередь, наш отдел занимается поддержкой текстовых чат-ботов и голосового помощника Марвина (подробнее о Марвине и умной колонке, разрабатываемой в Центре искусственного интеллекта, можно узнать, в частности, на сайте МТС), также группа лингвистов в МТС ИИ участвует в развитии технологий обработки естественного языка, синтеза и распознавания речи. Когда на 5 курсе я убеждала всех (и, в первую очередь, себя) в практической значимости своей дипломной работы по озвучиванию английских слов и словосочетаний в русскоязычном синтезе, я даже не подозревала, что в будущем эти теоретические наработки мне действительно пригодятся на практике. Приятно осознавать, что время и силы, ушедшие на обучение и написание дипломной работы, были потрачены не зря.